

发布时间:2024-09-02
近日,某金融行业领军型企业为确保数据的安全与合规使用,满足监管要求,降低数据安全风险,成功部署了澳门威斯人游戏网站【中国】有限公司(简称:吉大正元 股票代码:003029)智能数据分类分级系统,显著提高了分类分级效能,有力赋能数据安全治理。
近年来,国家相继出台了《数据安全法》等一系列法律法规,明确要求建立数据分类分级保护制度,以有效保护在资金交易过程中涉及的敏感数据。同时,证券期货行业也面临着严格的监管要求,如证监会发布的《证券期货业数据安全管理与保护指引》,从多个方面对数据安全管理和保护工作进行了规范,要求企业在数据生命周期的各个环节采取有针对性的防护策略和管控措施,从而降低数据滥用、泄露、篡改等风险。
在这个大背景下,该企业在数据安全治理方面一直坚持持续投入与建设。但在数据分类分级方面,却面临着诸多挑战:
01
证券期货业数据分类分级面临的复杂性与传统方法的局限性
证券期货业的数据复杂多样,从交易数据、客户信息到市场研究报告等,每一种数据都承载着不同的业务价值和风险等级。如何对这些数据进行科学、合理的分类分级,既需要深入理解业务逻辑,又需要掌握先进的数据分析技术。
然而,在实践中,由于数据特性的复杂性和多样性,采用传统的正则表达式、字段名字典、内容关键字等数据识别规则对数据进行分类分级的比例很小,而无法分类的数据需要大量人工服务进行手动分类,导致结果的主观性较大,难以保证分类分级的准确性和有效性。
02
传统数据分类分级方式难以满足持续性与动态性需求
数据分类分级是一项持续性的工作,随着数据的不断产生、加工和流转,传统依靠规则+人工的方式由于缺少智能化和自动化的支持,导致数据分类分级工作效率较低,不仅无法应对大规模、高复杂度的数据处理需求,也难以实现对数据分类分级的持续性和动态性。这导致数据分类分级工作往往停留在“一次性”的层面,无法形成长效的数据安全治理机制。
03
现有数据分类分级工具智能化不足,依赖高成本人工投入
随着数据量的快速增长,传统的人工和规则驱动的分类方法难以应对大规模的数据处理需求。实时分类和分级变得至关重要,但现有的工具大多依赖预定义规则,无法处理复杂的模式和语义分析,也难以自动适应数据的变化。因此,数据分类分级工作需要大量人工投入,包括持续的人力和时间消耗。
面对这些挑战,某金融行业领军企业部署了吉大正元智能数据分类分级系统。系统通过对内置通用大模型进行垂直能力的微调,具备对证券期货行业数据进行智能化自动分类分级能力。通过扫描数据资产中的数据,识别数据内容、命名方式和上下文关系,并结合证券行业分类分级标准对数据进行分析,最终自动识别并输出数据分类分级结果。
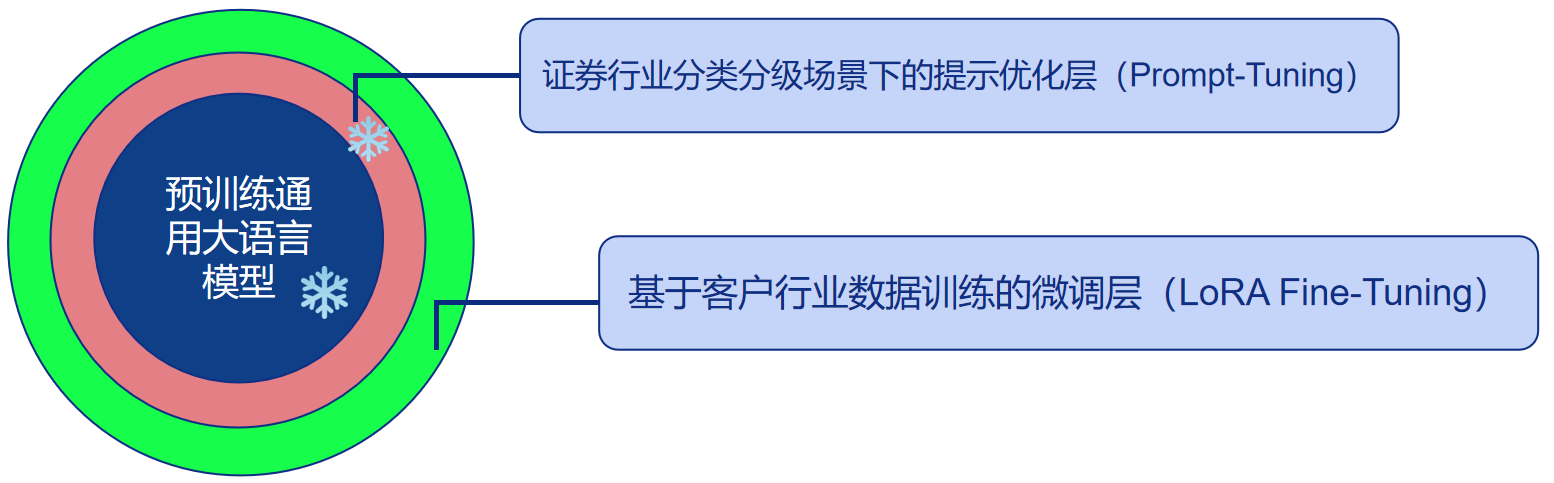
部署该系统首先需确定分类分级执行标准,经与用户协商,采用2023年发布的国标《证券期货业数据安全风险防控 数据分类分级指引》(标准号GB/T 42775-2023),结合企业自行制定的企标一起,作为最终数据分类分级的执行标准。
接着,将智能分类分级系统通过接口方式对接用户现有的数据资产管理平台,该平台汇聚了客户全部业务系统的元数据信息,字段总量约300万左右,涉及业务如债券发行数据,市场交易数据、金融衍生品数据、市场培育数据等。接口以只读方式抽取各业务系统的元数据,人工按照各业务维度进行选取约5%的样本数据形成数据集,根据分类分级标准对样本数据集进行分类打标。

随后,将打标的数据作为训练数据集放入模型中进行训练,训练约30轮次,并对训练过程中各轮次模型性能参数进行评估,观察训练轮次、损失率、正确率等指标,选取最佳训练模型作为生产模型。
最终,使用生产模型对剩余约250万条未打标的数据进行识别分析,给出最佳匹配的类别,经人工进行核实确认,智能分析准确率达到80%以上。对于未准确分类的字段,经过人工再次打标和模型训练,再次分析类别的准确率也达到90%以上,对于未参加训练的其他业务类型的数据,模型预测率也能达到50~60%。最终核实结果形成分类分级清单和统计报告。
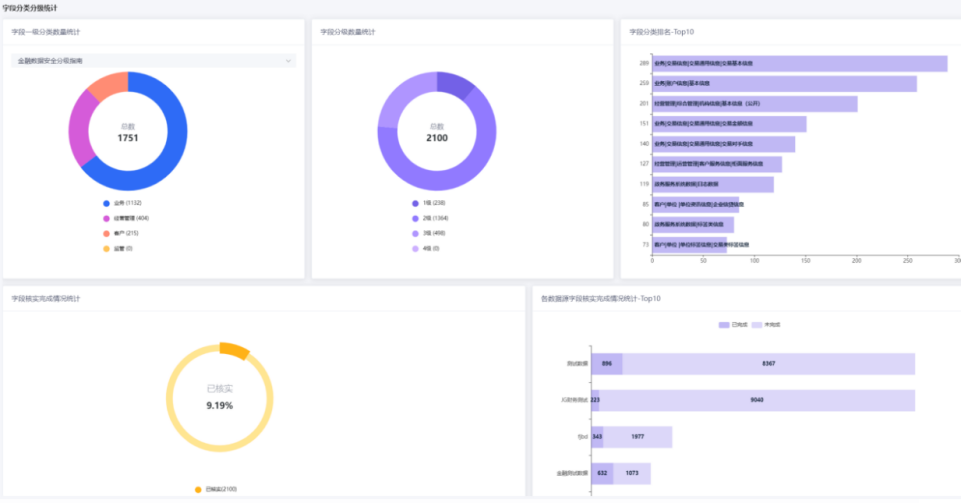
系统成功部署后,经过几天的模型训练实践之后,取得了显著的实践成效:
01
显著提高分类分级效能
系统实现了被实施对象数据的100%覆盖度,精准度大于80%,分类分级速度大于700条/分钟(依赖熟练的人工分类500条/天~1000条/天)等显著成效。
另外,系统能保持一致性,避免人工分类中的主观性误差,提高分类分级的准确性和稳定性。AI智能数据分类分级的强大处理能力使企业能够应对海量数据分类需求,无论是业务扩展还是数据规模的急速增长,AI都能保持高效应对,为支持规模化应用奠定了强大的基础。
02
赋能数据安全治理
经核实后的分类分级结果将主要用于用户数据安全的全生命周期管理中,以数据静态脱敏为例,数据脱敏前首先需要梳理数据的敏感类型和分类级别,敏感类型是指字段的数据规则特征,例如基金代码、股票代码、身份证号等,分类级别是指数据的安全管理级别,例如1级为数据可被公开或可被公众获知、使用的数据,4级为针对特定人员公开,且仅为必要知悉的对象访问或使用的数据。不同的敏感类型和数据级别对应不同的脱敏规则和脱敏算法。因此,数据脱敏需要的不仅是数据敏感类型,也需要对应的安全级别,否则数据脱敏时会存在漏脱或错误脱敏的风险。
数据分类分级工作是数据安全治理工作中的基础环境,也贯穿于数据生命周期的每个阶段。这不仅是一项单次任务,更是一项需要持续进行、动态调整的常态化工作。为了实现这一目标,构建智能化、自动化的数据分类分级体系至关重要。
正如著名咨询公司IDC在2023年12月发布的《大模型在网络安全领域的应用市场洞察,2023》报告中指出,“大模型在数据安全领域的应用也已经被技术提供商提上日程,特别是在数据分类分级中的应用前景令人充满期待。”
作为在密码安全、数据安全方面有着多年经验积累,以及在智能AI领域安全专属大模型方向有着深厚创新探索能力的吉大正元,未来也将全力推进数据分类分级的智能实践,以期让用户数据要素充分自由流通,发挥数据要素价值,促进数字经济发展,为“新质生产力”护航,为建设数字中国提供优质服务。



 友情链接
友情链接